- Finally, an Android tablet that I wouldn't mind putting my iPad Pro away for
- 8 communication strategy tips for IT leaders
- Why these $160 earbuds are my new favorite for work and travel over the AirPods
- US Offers $10 Million Reward for Tips About State-Linked RedLine Cybercriminals
- You can get an iPhone 16 for free with this Boost Mobile deal - no trade-in required

CUPS high availability
CUPS high availability
Presence high availability, a feature that is quite easy to enable, so why not use it if you run a multi-node environment. This is a quick post on how to enable it and what it does, based on CUPS version 8.6.4.
Cisco Unified Presence supports High Availability at a subcluster level. Both nodes in the subcluster must be running the same version of Cisco Unified Presence 8.x software for High Availability to work. This means that during a n 8.x software upgrade it, HA will need to be disabled to prevent replication issues (also as per upgrade guide). This, because if presence detects the situation where both nodes in the subcluster think that they own the same user, both nodes will go into a failed state, and you will need to perform a manual recovery from the Cluster Topology web interface. I have found in some cases when upgrading, that although all services are up on both nodes, and all nodes have users balanced, it would still not allow logon on certain servers, for some unknown reason. At which point a reboot was required. Something to keep in mind.
Back to the set up, in CUPS, if you go to SYSTEM>Cluster Topology>DefaultCluster, you will see the following if HA is enabled:
 |
| Fig.1. High availability and fail over configuration |
As you can see, very easy to enable and disable. in this particular example users are balanced between two servers. But you can also register users in ACTIVE/STANDBY fashion (use the sync agent service parameters to do this).
Cisco Unified Presence automatically detects failover in a subcluster by monitoring the heartbeat and monitoring the critical services on the peer node. When Cisco Unified Presence detects failover, it automatically moves all user to the backup node. From the Cisco Unified Presence Administration interface, you can initiate a manual fallback to the active node.
Cisco Unified Presence does not perform an automatic fallback to the active node after failover. This means that you must manually perform the fallback from the Cluster Topology interface (see figure 1), otherwise the failed over users will remain on the backup node.
Failover detection is twofold:
heart beat between the two servers. The heart beat interval and timeout can be configured through the service parameters. (see Figure 2). Be carefull when changing the default values, decreasing timeout values could make the deployment unstable! Figure 2 shows the default values.
- service monitoring of critical services on both servers. Each node monitors a list of critical services. if a node detects that one or more of its critical services is not running for a period of “critical service down delay” (fig.2), it will instruct the peer node to initiate failover. The service that are monitored for this purpose are: Cisco DB (internal IDS database), Cisco UP Presence Engine , Cisco UP XCP Router, Cisco UP Message Archive, Cisco UP SIP Proxy , Cisco UP XCP SIP Federation Connection Manager.
 |
| Figure 2 – Hear beat interval and time out value configuration |
Figure 3 show the node details and what the status is of each of these monitored services. SYSTEM>TOPOLOGY>SERVER Details
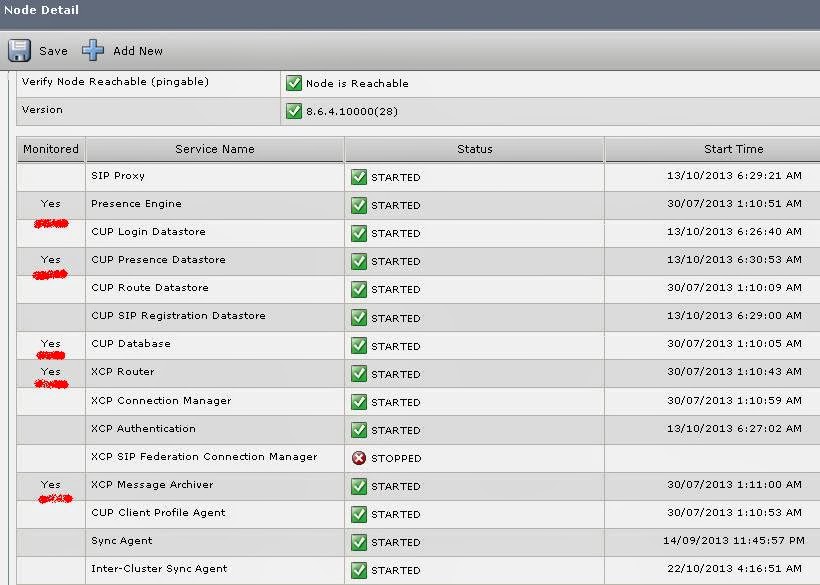 |
| Figure 3 – HA monitored services details |
This monitoring of critical services means, that if you would, for instance, manually stop the Presence engine, for longer than 90 seconds (critical services down delay), fail over would occur.
The underlying mechanism that deals with fail over is the Cisco UP server recovery manager (SRM). It manages all state changes on a node. these state changes could be automatic or initiated by an administrator (manual, by hitting the Failover button in figure 1). SRM is reponsible for the user moves once it detects that fail over has occurred. It is the SRM on the peer node, not the failed note that performs the user move operation. please note that user moves are throttled (see figure 4)
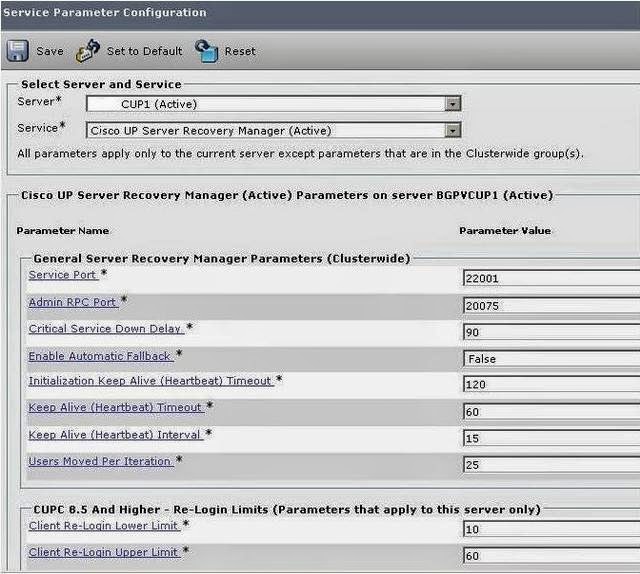 |
| Fig.4 SRM service parameters |
In terms of manual fail over, again see figure 1. If you hit the “FAIL OVER” button, this will move all active users over to the backup node. In reverse order you can initiate a FALLBACK, back to the active server. When doing a manual fail over, the SRM will stop all relevant service on the failing node. This is important, becuase it will no longer allow any communications with CUCM, so the PUblish Trunk, as configured on CUCM, will fail over to the second destination IP address/DNS name in its configuration.
I have noticed, that during an upgrade that I did (8.6.4>8.6.5), when installing the new software on the inactive partition, this caused a fail over from the node that I was doing the install on. This was most likely caused by an unresponsive service. The alert that we got for this fail over was triggered by SRM. So, something to be aware of, as you would not expect an impact, when installing new software on an inactive partition.
Redundant log in for Jabber
Redundant log in for jabber, how can this be achieved automatically? Its’s actually not that hard. there are two ways to do this (unless someone wants to point out other methods; I’m all ears). one of these methods I have already addressed in a previous post and uses SRV records.
http://ciscoshizzle.blogspot.com.au/2013/05/using-srv-records-for-redundancy-and.html
http://ciscoshizzle.blogspot.com.au/2013/05/using-srv-records-for-redundancy-and.html
The second method is by means of DNS. For example you use the DNS name “cup” as the presence server in Jabber, create to DNS A records, each resolving the name into the IP address of each server. like so:
> nslookup cup
Server: cup.dogtel.com.au
Addresses: 10.10.10.25, 10.10.20.25
